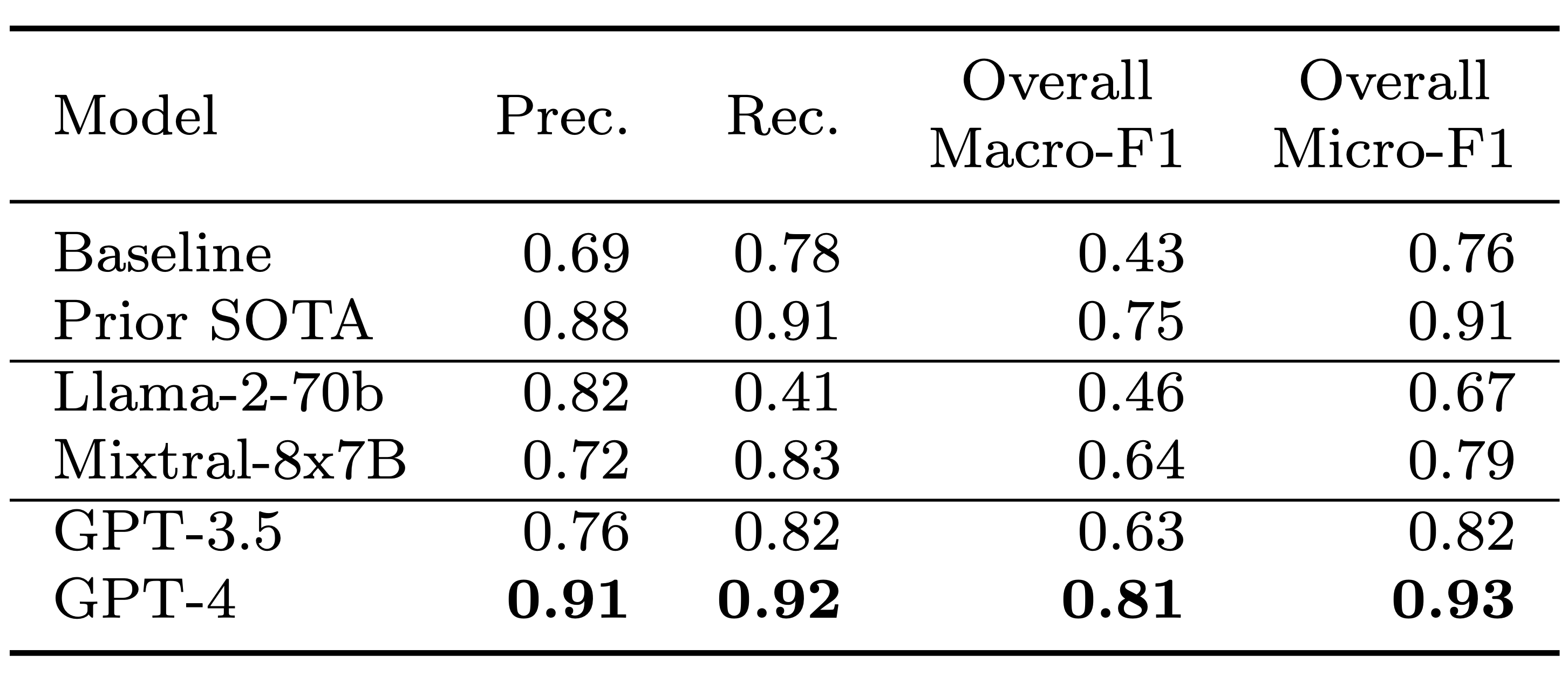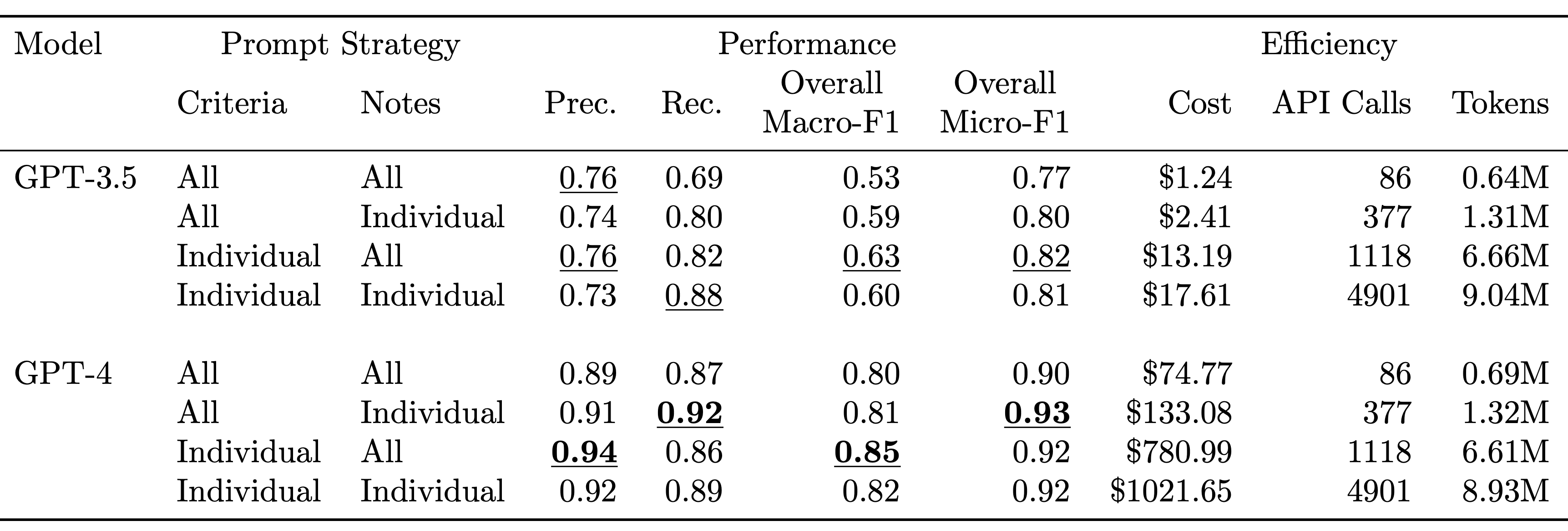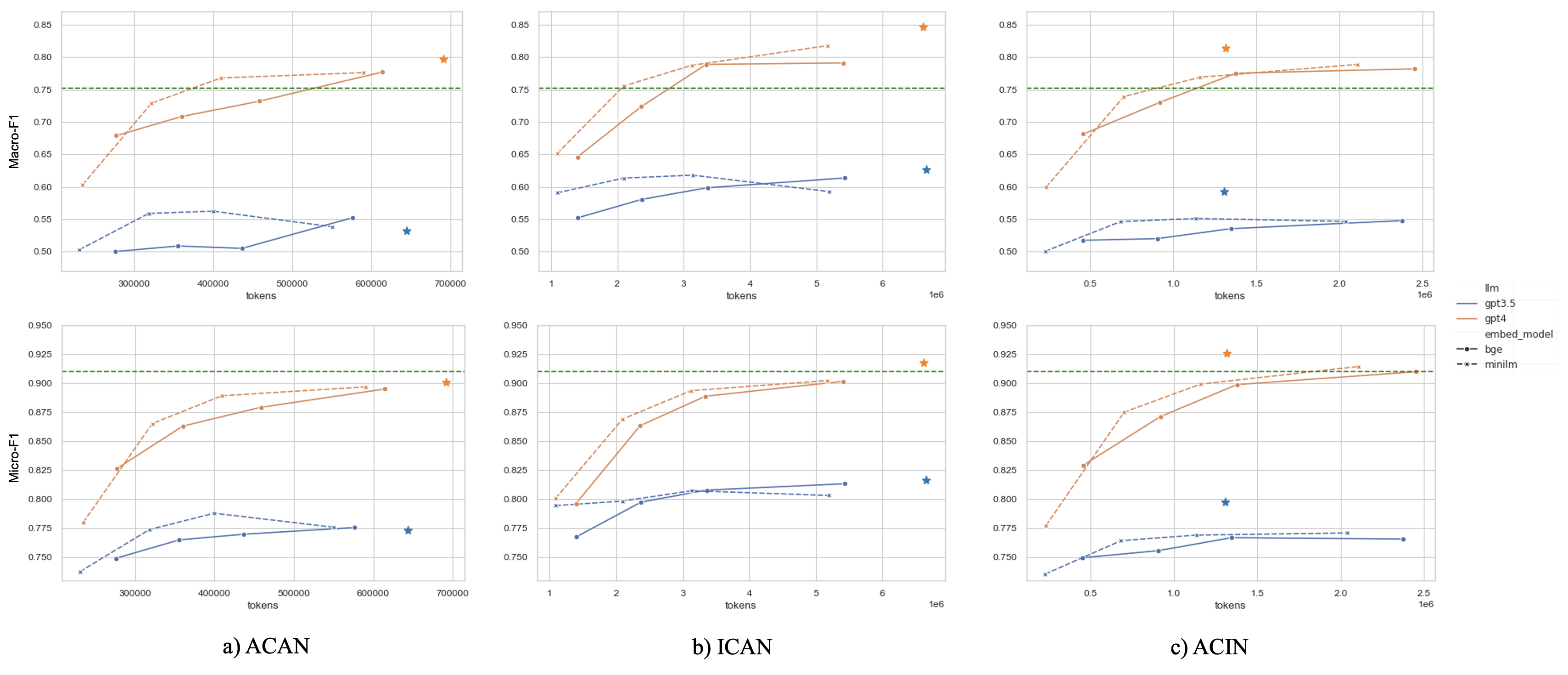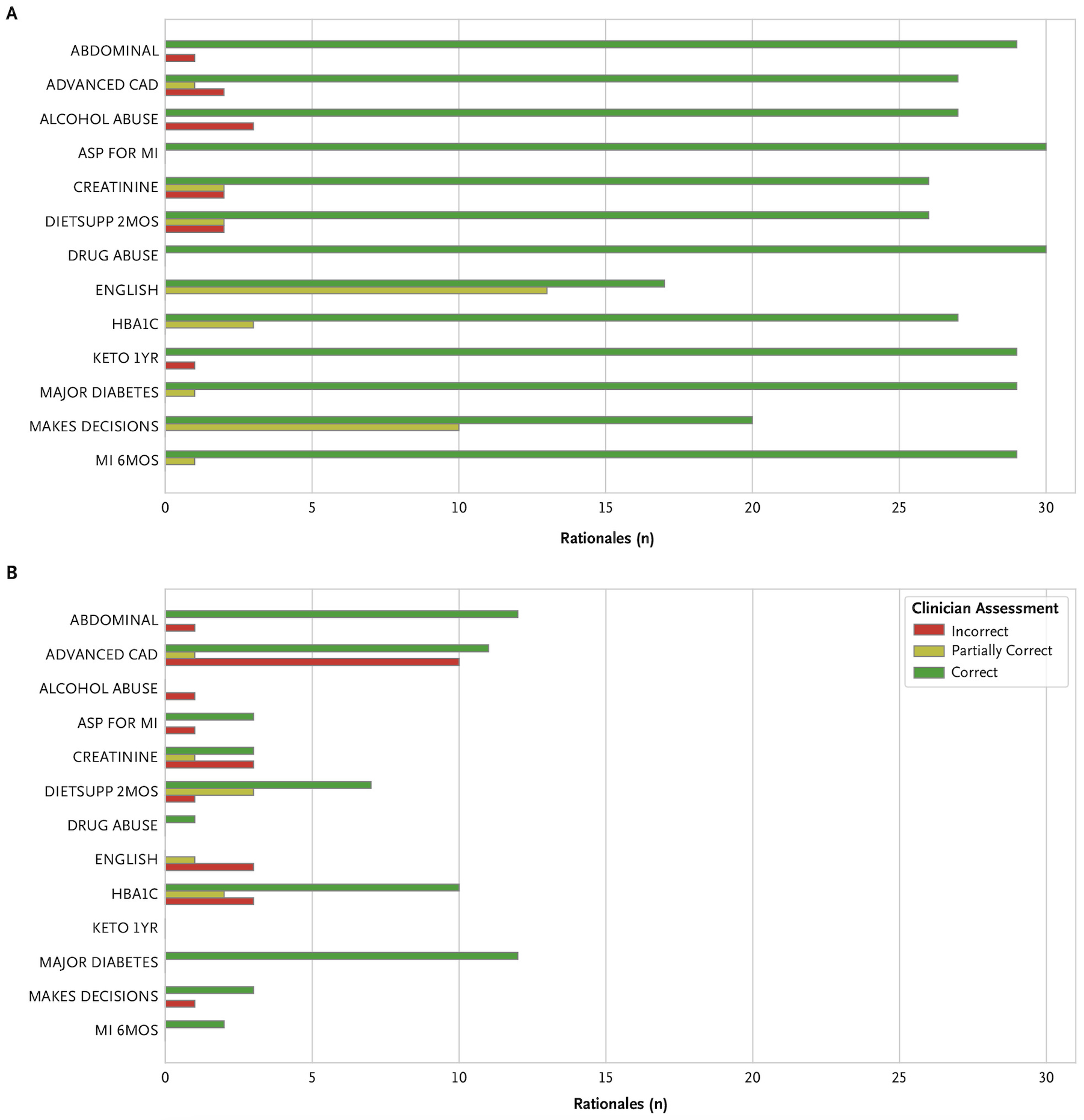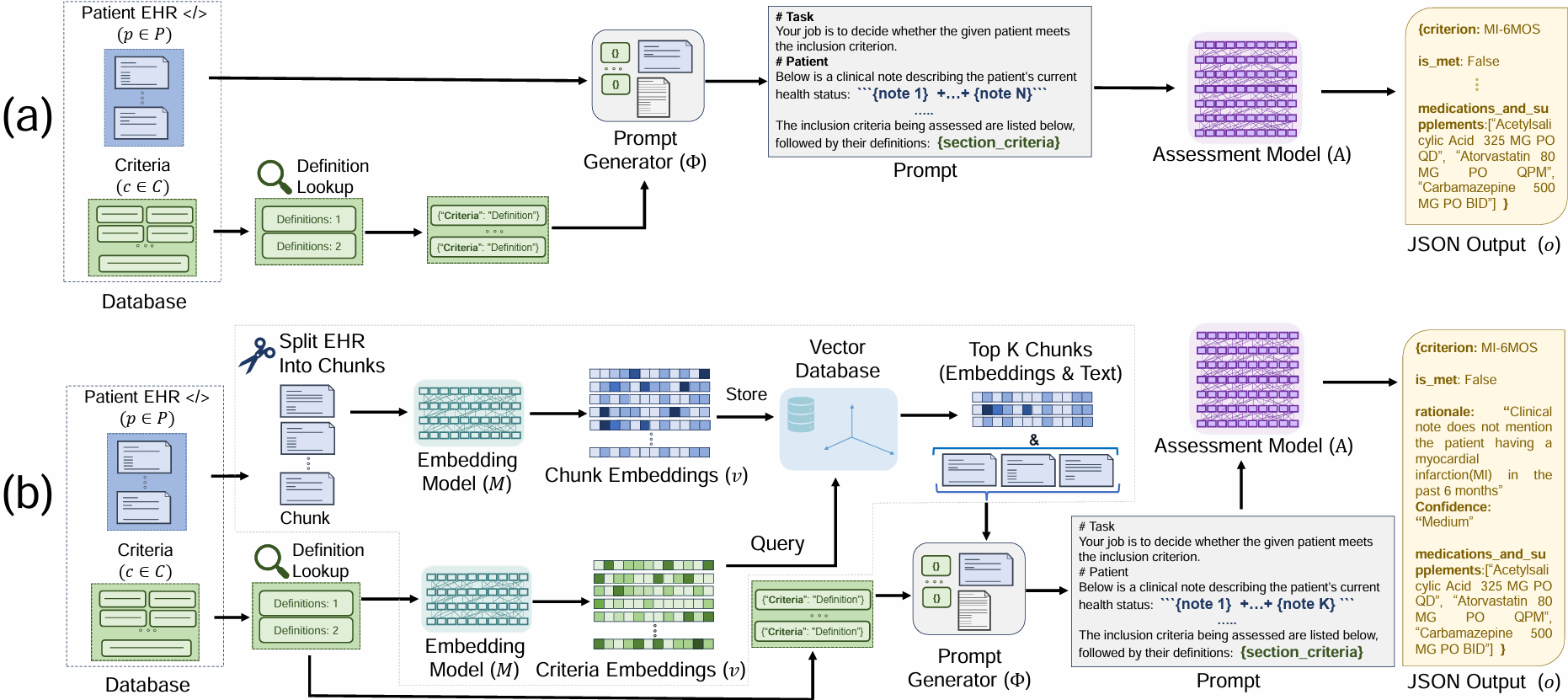
TL;DR: We explore zero-shot clinical trial patient matching with large language models (LLMs) under two system designs (traditional prompting vs reduced prompting via retrieval augmentation):
(a) We inject the patient's entire set of notes into a prompt input into an Assessment LLM (e.g. GPT-4) for evaluation. (b) In our two-stage retrieval pipeline, we first query the top-k most relevant chunks from the patient's notes, then inject only those top-k chunks into the prompt input into an Assessment LLM. Both paradigms are compared using the same prompting strategies, with the only distinction being the amount of patient information included in the prompt.